注:本系列第一章推送门:阿里云郑晓:浅谈GPU虚拟化技术(第一章) GPU虚拟化发展史
第二章 GPU虚拟化方案之——GPU直通模式
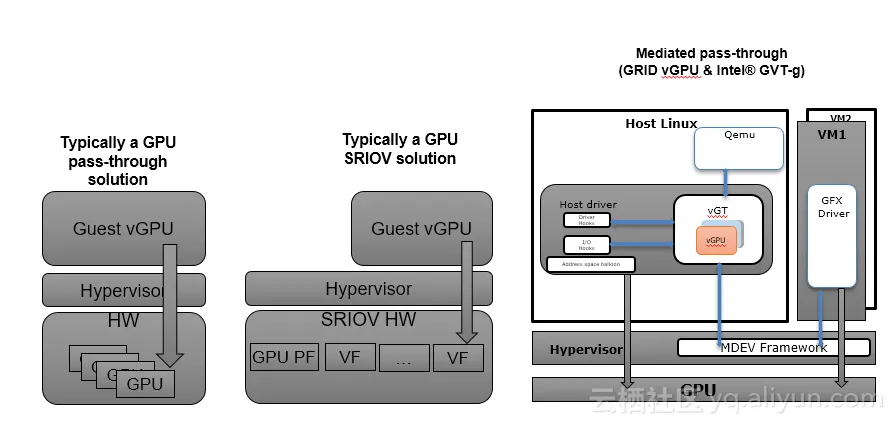
目前流行的商用GPU虚拟化方案可以分为以下几类:GPU 直通模式,GPU SRIOV 模式,GPU 半虚拟化(mediated passthrough:包括Intel GVT-g和Nvidia GRID vGPU),VMWare的GPU全虚拟化(vSGA)。当然也有尚未成熟处于玩票性质的virtio GPU等等。
各种方案的架构如下图,相信大家简单看图表也不会有什么大感觉:)
接下来我们简单介绍下GPU直通虚拟化(passthrough)方案的方方面面,并会在后续章节介绍vGPU分片虚拟化和SRIOV方案技术框架结构。
GPU直通模式是最早采用也最成熟的方案。三家(Nvidia Tesla,AMD FirePro,Intel Gen8/Gen9)都有支持。
直通模式的实现依赖于IOMMU的功能。VTD对IOVA的地址转换使得直通设备可以在硬件层次直接使用GPA(Guest Physical Address)地址。
直通模式的技术方案与其他任何PCI直通没有任何区别。由于GPU的复杂性和安全隔离的要求,GPU直通技术相对于任何其他设备来说,会有额外的PCI 配置空间模拟和MMIO的拦截(参见QEMU VFIO quirk机制)。比如Hypervisor或者Device Module 不会允许虚拟机对GPU硬件关键寄存器的完全的访问权限,一些高权限的操作会被直接拦截。大家或许已经意识到原来直通设备也是有MMIO模拟和拦截的。这对于我们理解GPU 半虚拟化很有帮助。
PCI 直通的技术实现:所有直通设备的PCI 配置空间都是模拟的。而且基本上都只模拟256 Bytes的传统PCI设备,很少有模拟PCIE设备整个4KB大小的。而对PCI设备的PCI bars则绝大部分被mmap到qemu进程空间,并在虚拟机首次访问设备PCI bars的时候建立EPT 页表映射,从而保证了设备访问的高性能。想了解细节的同学可以去参考Linux kernel document: vfio.txt
PCI 直通架构详见下图。
直通模式是对比物理机性能损耗最小,硬件驱动无需修改的方案,被各大公用云厂商广泛采用。对于支持直通的GPU而言,直通模式没有对可支持的GPU数量做限制,也没有对GPU功能性做阉割。GPU厂家的绝大多数新功能可以在直通模式下无修改地支持。
直通模式的优点:
1.性能:如前所述,直通模式是性能损耗最小的
对于公有云厂商来说吸引租客上云的关键就是性能。用户在把业务搬迁上云之后的第一件事永远是作对比:业务在云端的处理能力与尚未上云的本地业务处理能力作对比。相当多的客户甚至因为1%的性能损失而拒绝采用GPU云服务器。
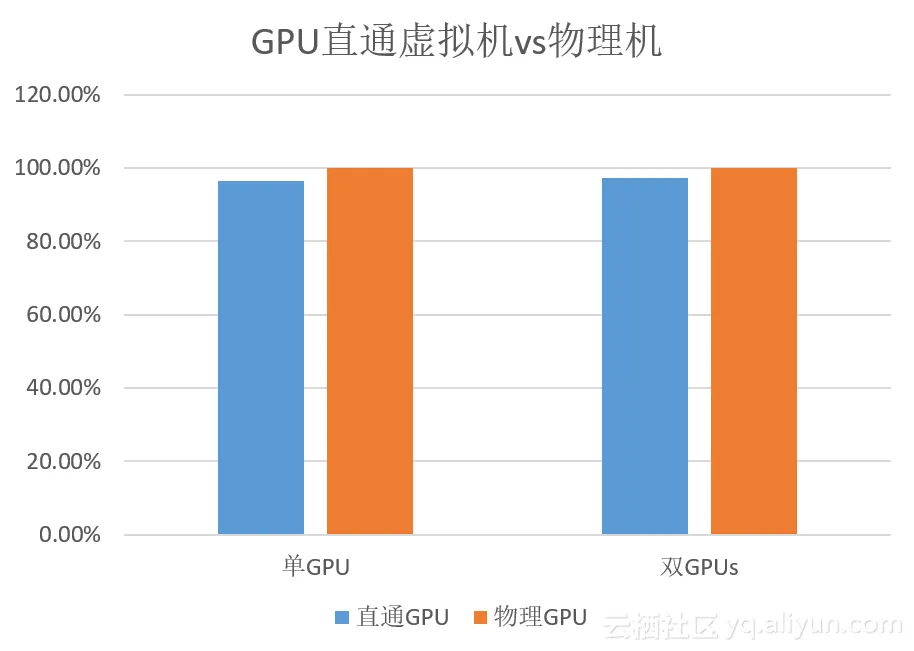
Nvidia GPU 直通模式下与物理机的性能对比见下图:(大部分单GPU应用场景的性能对比可以达到96%左右)
大家或许会很好奇这4%的性能损失跑哪里去了?我们可以在介绍GPU分片虚拟化的时候继续讨论。
2.功能兼容性好
GPU的技术一直在发展。从原先的只针对3D图形加速渲染,到后续视频硬件编解码的支持,再到后续人工智能,机器学习的大规模运用,以及最新的多GPU互联互通等,直通设备对新功能的兼容性很好得力于对虚拟机GPU驱动的兼容性。GPU厂商开发的针对物理机的驱动,一般情况下可以不做任何修改地放到虚拟机内部执行。而随着GPU虚拟化的影响力逐渐扩大,一个GPU驱动同时支持物理机和虚拟机直通已经变成出厂的基本要求。
3.技术简单,运维成本低,对GPU厂商没有依赖降低运维成本是提高云计算公司成本的有效方法。技术越简单,运行越稳定,一直是至理名言。
如果一个公司需要搬迁GPU服务器到云端的话,那么依赖于GPU直通技术,或许在几天之内就可以搭建一个原型出来。
最关键的是,直通技术完全不依赖于GPU的开发厂家。有些GPU的厂商甚至都不知道自家的GPU被用到数据中心,直到对方发布了GPU云服务器。
直通模式的缺点:
1.不支持热迁移(Live Migration)
与任何直通虚拟化的设备一样,直通设备的一个明显缺点是不支持热迁移。事实上在GPU硬件层面是完全支持热迁移技术的。现代GPU的设计理念都有一个上下文切换的概念(context switch or world switch),一个context在执行的过程中是完全可以被硬件中断,并切换到另外一个context上执行,比如Windows GPU workload的抢占功能。大家如果打开windows右下角的时钟表盘,可以看到秒表的跳动,每一次秒表的跳动都是一次GPU抢占。无论当前应用程序在做什么样规格的渲染,Windows都会挂起当前渲染任务,并切换到表盘显示的上下文,待表盘更新完毕再切换回之前被挂起的任务继续做渲染。(扯远了,关于GPU虚拟化的热迁移技术,我会放到高阶技术介绍章节中。)
既然GPU 硬件是支持热迁移的,那么主流虚拟化(KVM/Xen)为什么不去支持呢?因为GPU实在是太复杂,各厂实现又大相径庭。要实现一个GPU的热迁移,没有GPU硬件厂商的协助是绝无不可能的。而且GPU硬件研发属于厂家的核心竞争力,驱动开发也基本上属于闭源状态。只有Intel的核显GPU 有公开版的一部分硬件规范和开源i915驱动。其他厂家只提供二进制驱动。
2.不支持GPU资源的分割不支持GPU资源的分割算不上GPU直通的缺点。此缺点完全是对比SRIOV和GPU半虚拟化来说。有一些应用场景,客户或许对GPU高并行计算性能并不关心,反而对GPU虚拟化的多虚拟机支持有很高要求。比如对于VDI应用,每一个虚拟机对GPU渲染计算能力的要求都非常小,相反应用场景需要一个GPU去支持多达32个虚拟机,那么直通设备就完全没办法适用。成本上考虑不可能让每个虚拟机分配一个GPU硬件,实现上也不可能有一个主板插上多达32个GPU的。
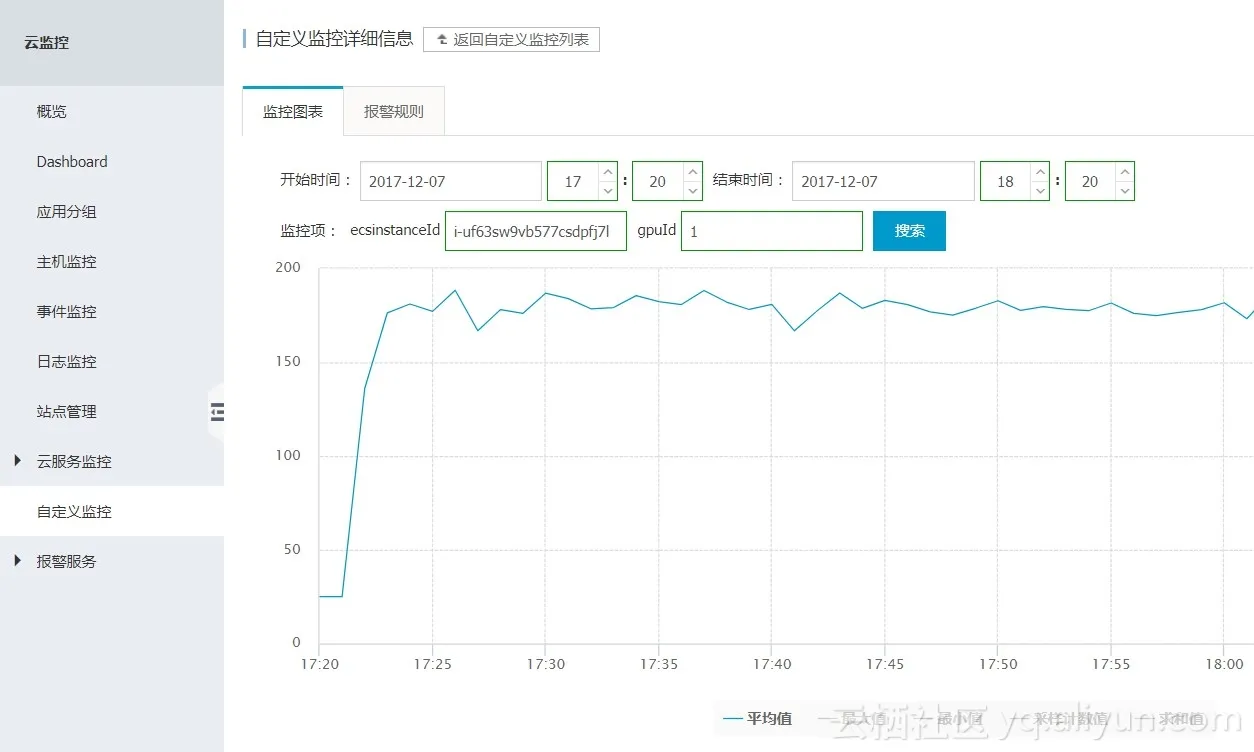
3.监控缺失
云计算公司对运维的基本要求就是能图表化当前资源的各种状态。比如GPU虚拟机是否正常,GPU 当前负荷,GPU当前温度,GPU的内存使用率等等。由于GPU直通是让虚拟机直接访问GPU硬件,在宿主机上只有一个Pseudo PCI驱动,从而无法拿到有效信息。没有这些监控数据的支持,GPU云服务器就是一个个孤岛而不能形成统一调度和运维。对运维人员来说,维护这样成千上万GPU的集群就是一个灾难。
下图是阿里云ECS GPU团队通过其他手段实现的GPU云监控图表: