宋吉科,腾讯云异构计算研发负责人,专注系统虚拟化、操作系统内核十多年,KVM平台上第一个GPU全虚拟化项目KVMGT作者,对GPU、PCIe有深入的研究。
〇、本文写作背景大约 2 年前,在腾讯内网,笔者和很多同事讨论了 GPU 虚拟化的现状和问题。从那以后,出现了一些新的研究方向,并且,有些业界变化,可能会彻底颠覆掉原来的一些论断。
但这里并不是要重新介绍完整的 GPU 虚拟化的方案谱系。而是,我们将聚焦在英伟达 GPU + CUDA 计算领域,介绍下我们最新的技术突破 qGPU,以及它的意义究竟是什么。关于 GPU 虚拟化的历史性介绍,我将直接摘抄当时的讨论。
这也不是一篇介绍 TKE qGPU 产品特性的文章。而是,我们将潜入到前所未有的深度,去探索 GPU 调度和 QoS 的本质。本文也不是巨细靡遗的系统性探索,但你可以在这里看到别处不曾出现过的知识。
本文涉及对一些厂商的推测性技术介绍,不保证准确性。
一、术语介绍GPU ————— Graphics Processing Unit,显卡
CUDA ———— Compute Unified Device Architecture,英伟达 2006 年推出的计算 API
VT/VT-x/VT-d — Intel Virtualization Technology。-x 表示 x86 CPU,-d 表示 Device。
SVM ————— AMD Secure Virtual Machine。AMD 的等价于 Intel VT-x 的技术。
EPT ————— Extended Page Table,Intel 的 CPU 虚拟化中的页表虚拟化硬件支持。
NPT ————— Nested Page Table,AMD 的等价于 Intel EPT 的技术。
SR-IOV ——— Single Root I/O Virtualization。PCI-SIG 2007 年推出的 PCIe 虚拟化技术。
PF ————— Physical Function,亦即物理卡
VF ————— Virtual Function,亦即 SR-IOV 的虚拟 PCIe 设备
MMIO ——— Memory Mapped I/O。设备上的寄存器或存储,CPU 以内存读写指令来访问。
CSR ———— Control & Status Register,设备上的用于控制、或反映状态的寄存器。CSR 通常以 MMIO 的方式访问。
UMD ———— User Mode Driver。GPU 的用户态驱动程序,例如 CUDA 的 UMD 是 libcuda.so
KMD ———— Kernel Mode Driver。GPU 的 PCIe 驱动,例如英伟达 GPU 的 KMD 是 nvidia.ko
GVA ———— Guest Virtual Address,VM 中的 CPU 虚拟地址
GPA ———— Guest Physical Address,VM 中的物理地址
HPA ———— Host Physical Address,Host 看到的物理地址
IOVA ———— I/O Virtual Address,设备发出去的 DMA 地址
PCIe TLP —— PCIe Transaction Layer Packet
BDF ———— Bus/Device/Function,一个 PCIe/PCI 功能的 ID
MPT ———— Mediated Pass-Through,受控直通,一种设备虚拟化的实现方式
MDEV ——— Mediated Device,Linux 中的 MPT 实现
PRM ———— Programming Reference Manual,硬件的编程手册
MIG ———— Multi-Instance GPU,Ampere 架构高端 GPU 如 A100 支持的一种 hardware partition 方案
二、GPU 虚拟化的历史和谱系2.1 GPU 能做什么GPU 天然适合向量计算。常用场景及 API:
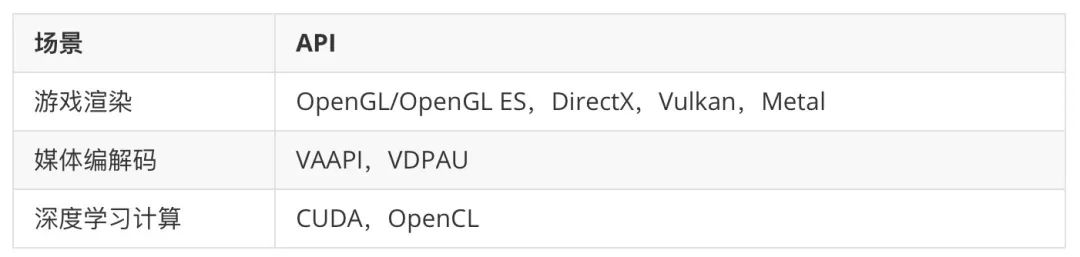
此外还有加解密、哈希等场景,例如近些年来的挖矿。渲染是 GPU 诞生之初的应用: GPU 的 G 就是 Graphics —— 图形。
桌面、服务器级别的 GPU,长期以来仅有三家厂商:
英伟达:GPU 的王者。主要研发力量在美国和印度。
AMD/ATI:ATI 于 2006 年被 AMD 收购。渲染稍逊英伟达,计算的差距更大。
Intel:长期只有集成显卡,近年来开始推独立显卡。
2006 这一年,GPU 工业界发生了三件大事: ATI 被 AMD 收购;nVidia 黄仁勋提出了 CUDA 计算;Intel 宣布要研发独立显卡。
日光之下并无新事。如同经常发生的,这些事有成功有失败: Intel 很快就放弃了它的独立显卡,直到 2018 才终于明白过来自己到底放弃了什么,开始决心生产独立显卡;AMD 整合 ATI 不太成功,整个公司差点被拖死,危急时公司股票跌到不足 2 美元;而当时不被看好的 CUDA,则在几年后取得了不可思议的成功。
从 2012 年开始,人工智能领域的深度学习方法开始崛起,此时 CUDA 受到青睐,并很快统治了这个领域。
2.2 系统虚拟化和 OS 虚拟化系统虚拟化演化之路,起初是和 GPU 的演化完全正交的:
1998 年,VMWare 公司成立,采用 Binary Translation 方式,实现了系统虚拟化。
2001 年,剑桥大学 Xen Source,提出了 PV 虚拟化(Para-Virtualization),亦即 Guest-Host 的主动协作来实现虚拟化。
2005 年,Intel 提出了 VT,最初实现是安腾 CPU 上的 VT-i (VT for Itanium),很快就有了 x86 上的 VT-x。
2007 年,Intel 提出了 VT-d (VT for Device),亦即 x86 上的 IOMMU。
2008 年,Intel 提出了 EPT,支持了内存虚拟化。
2010 年,Linux 中的 PV Hypervisor lguest 的作者,Rusty Russell(他更有名的作品是 iptables/netfilter),提出了 VirtIO,一种 Guest-Host 的 PV 设备虚拟化方案。
应该可以说,在 PV 时代和 Binary Translation 时代,虚拟化是危险的。只有当 VT 在硬件层面解决了 CPU 的隔离、保证了安全性之后,公有云才成为可能。VT-x 于 2005 ~ 2006 年出现,亚马逊 AWS 于 2006 年就提出云计算,这是非常有远见的。
系统的三个要素: CPU,内存,设备。CPU 虚拟化由 VT-x/SVM 解决,内存虚拟化由 EPT/NPT 解决,这些都是非常确定的。但设备虚拟化呢?它的情况要复杂的多,不管是 VirtIO,还是 VT-d,都不能彻底解决设备虚拟化的问题,这些我们稍后还会谈到。
除了这种完整的系统虚拟化,还有一种也往往被称作「虚拟化」的方式: 从 OS 级别,把一系列的 library 和 process 捆绑在一个环境中,但所有的环境共享同一个 OS Kernel。
严格来说,这种容器技术,和以 KVM 为代表的系统虚拟化,有着本质的区别。随着容器的流行,「虚拟化」这个术语,也被用来指称这种 OS 级别的容器技术。因此我们也从众,把它也算作虚拟化的一种 —— 只不过为了区分,称之为「OS 虚拟化」。
这种 OS 虚拟化最初于 2005 年,由 Sun 公司在 Solaris 10 上实现,名为「Solaris Zone」。Linux 在 2007 ~ 2008 开始跟进,接下来有了 LXC 容器等;到了 2013 年,Docker 横空出世,彻底改变了软件分发的生态,成为事实上的标准。
2.3 GPU 虚拟化的谱系2.3.1 作为 PCIe 设备的 GPU不考虑嵌入式平台的话,那么,GPU 首先是一个 PCIe 设备。GPU 的虚拟化,还是要首先从 PCIe 设备虚拟化角度来考虑。
那么一个 PCIe 设备,有什么资源?有什么能力?
2 种资源:
配置空间
MMIO
(有的还有 PIO 和 Option ROM,此略)
2 种能力:
中断能力
DMA 能力
一个典型的 GPU 设备的工作流程是:
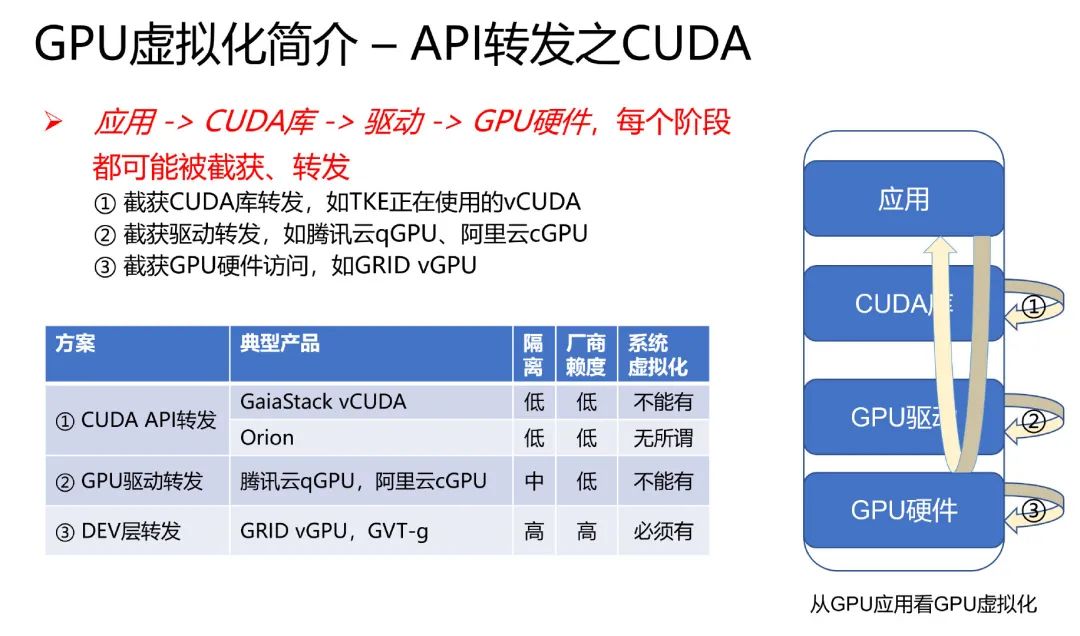
应用层调用 GPU 支持的某个 API,如 OpenGL 或 CUDA
OpenGL 或 CUDA 库,通过 UMD (User Mode Driver),提交 workload 到 KMD (Kernel Mode Driver)
KMD 写 CSR MMIO,把它提交给 GPU 硬件
GPU 硬件开始工作... 完成后,DMA 到内存,发出中断给 CPU
CPU 找到中断处理程序 —— KMD 此前向 OS Kernel 注册过的 —— 调用它
中断处理程序找到是哪个 workload 被执行完毕了,...最终驱动唤醒相关的应用
2.3.2 PCIe 直通我们首先来到 GPU 虚拟化的最保守的实现: PCIe 设备直通。
如前述,一个 PCIe 设备拥有 2 种资源、2 种能力。你把这 2 种资源都(直接或间接地)交给 VM、针对这 2 种能力都把设备和 VM 接通,那么,VM 就能完整使用这个 PCIe 设备,就像在物理机上一样。这种方案,我们称之为 PCIe 直通(PCIe Pass-Through)。它只能 1:1,不支持 1:N。其实并不能算真正的虚拟化,也没有超卖的可能性。
VM 中,使用的是原生的 GPU 驱动。它向 VM 内核分配内存,把 GPA 填入到 GPU 的 CSR 寄存器,GPU 用它作为 IOVA 来发起 DMA 访问,VT-d 保证把 GPA 翻译为正确的 HPA,从而 DMA 到达正确的物理内存。
PCIe 协议,在事务层(Transaction Layer),有多种 TLP,DMA 即是其中的一种: MRd/MWr。在这种 TLP 中,必须携带发起者的 Routing ID,而在 IOMMU 中,就根据这样的 Routing ID,可以使用不同的 IOMMU 页表进行翻译。
很显然,PCIe 直通只能支持 1:1 的场景,无法满足 1:N 的需求。
2.3.3 SR-IOV那么,业界对 1:N 的 PCIe 虚拟化是如何实现的呢?我们首先就会想到 SR-IOV。SR-IOV 是 PCI-SIG 在 2007 年推出的规范,目的就是 PCIe 设备的虚拟化。SR-IOV 的本质是什么?考虑我们说过的 2 种资源和 2 种能力,来看看一个 VF 有什么:
配置空间是虚拟的(特权资源)
MMIO 是物理的
中断和 DMA,因为 VF 有自己的 PCIe 协议层的标识(Routing ID,就是 BDF),从而拥有独立的地址空间。
那么,什么设备适合实现 SR-IOV?其实无非是要满足两点:
硬件资源要容易 partition
无状态(至少要接近无状态)
常见 PCIe 设备中,最适合 SR-IOV 的就是网卡了: 一或多对 TX/RX queue + 一或多个中断,结合上一个 Routing ID,就可以抽象为一个 VF。而且它是近乎无状态的。
试考虑 NVMe 设备,它的资源也很容易 partition,但是它有存储数据,因此在实现 SR-IOV 方面,就会有更多的顾虑。
回到 GPU 虚拟化:为什么 2007 年就出现 SR-IOV 规范、直到 2015 业界才出现第一个「表面上的」SRIOV-capable GPU【1】?这是因为,虽然 GPU 基本也是无状态的,但是它的硬件复杂度极高,远远超出 NIC、NVMe 这些,导致硬件资源的 partition 很难实现。
注释
【1】 AMD S7150 GPU。腾讯云 GA2 机型使用。
表面上它支持 SR-IOV,但事实上硬件只是做了 VF 在 PCIe 层的抽象。Host 上还需要一个 Virtualization-Aware 的 pGPU 驱动,负责 VF 的模拟和调度。
2.3.4 API 转发因此,在业界长期缺乏 SRIOV-capable GPU、又有强烈的 1:N 需求的情形下,就有更 high-level 的方案出现了。我们首先回到 GPU 应用的场景:
渲染(OpenGL、DirectX,etc.)
计算(CUDA,OpenCL)
媒体编解码(VAAPI...)
业界就从这些 API 入手,在软件层面实现了「GPU 虚拟化」。以 AWS Elastic GPU 为例:
VM 中看不到真的或假的 GPU,但可以调用 OpenGL API 进行渲染
在 OpenGL API 层,软件捕捉到该调用,转发给 Host
Host 请求 GPU 进行渲染
Host 把渲染的结果,转发给 VM
API 层的 GPU 虚拟化是目前业界应用最广泛的 GPU 虚拟化方案。它的好处是:
灵活。1:N 的 N,想定为多少,软件可自行决定;哪个 VM 的优先级高,哪个 VM 的优先级低,同理。
不依赖于 GPU 硬件厂商。微软、VMWare、Citrix、华为……都可以实现。这些 API 总归是公开的。
不限于系统虚拟化环境。容器也好,普通的物理机也好,都可以 API 转发到远端。
缺点呢?
复杂度极高。同一功能有多套 API(渲染的 DirectX 和 OpenGL),同一套 API 还有不同版本(如 DirectX 9 和 DirectX 11),兼容性就复杂的要命。
功能不完整。计算渲染媒体都支持的 API 转发方案,还没听说过。并且,编解码甚至还不存在业界公用的 API!【1】
注释
【1】 Vulkan 的编解码支持,spec 刚刚添加,有望被所有 GPU 厂商支持。见下「未来展望」部分。
2.3.5 MPT/MDEV/vGPU鉴于这些困难,业界就出现了 SR-IOV、API 转发之外的第三种方案。我们称之为 MPT(Mediated Pass-Through,受控的直通)。MPT 本质上是一种通用的 PCIe 设备虚拟化方案,甚至也可以用于 PCIe 之外的设备。它的基本思路是:
敏感资源如配置空间,是虚拟的
关键资源如 MMIO(CSR 部分),是虚拟的,以便 trap-and-emulate
性能关键资源如 MMIO(GPU 显存、NVMe CMB 等),硬件 partition 后直接赋给 VM
Host 上必须存在一个 Virtualization-Aware 的驱动程序,以负责模拟和调度,它实际上是 vGPU 的 device-model
这样,VM 中就能看到一个「看似」完整的 GPU PCIe 设备,它也可以 attach 原生的 GPU 驱动。以渲染为例,vGPU 的基本工作流程是:
VM 中的 GPU 驱动,准备好一块内存,保存的是渲染 workload
VM 中的 GPU 驱动,把这块内存的物理地址(GPA),写入到 MMIO CSR 中
Host/Hypervisor/驱动: 捕捉到这次的 MMIO CSR 写操作,拿到了 GPA
Host/Hypervisor/驱动: 把 GPA 转换成 HPA,并 pin 住相应的内存页
Host/Hypervisor/驱动: 把 HPA(而不是 GPA),写入到 pGPU 的真实的 MMIO CSR 中
pGPU 工作,完成这个渲染 workload,并发送中断给驱动
驱动找到该中断对应哪个 workload —— 当初我是为哪个 vGPU 提交的这个 workload?—— 并注入一个虚拟的中断到相应的 VM 中
VM 中的 GPU 驱动,收到中断,知道该 workload 已完成、结果在内存中
这就是 nVidia GRID vGPU、Intel GVT-g(KVMGT、XenGT)的基本实现思路。一般认为 graphics stack 是 OS 中最复杂的,加上虚拟化之后复杂度更是暴增,任何地方出现一个编程错误,调试起来都是无比痛苦。但只要稳定下来,这种 MPT 方案,就能兼顾 1:N 灵活性、高性能、渲染计算媒体的功能完整性...是不是很完美?
其实也不是。
该方案最大的缺陷,是必须有一个 pGPU 驱动,负责 vGPU 的模拟和调度工作。逻辑上它相当于一个实现在内核态的 device-model。而且,由于 GPU 硬件通常并不公开其 PRM,所以事实上就只有 GPU 厂商才有能力提供这样的 Virtualization-Aware pGPU 驱动。使用了厂商提供的 MPT 方案,事实上就形成了对厂商的依赖。
2.3.6 SR-IOV: revisited重新回到 GPU 的 SR-IOV。AMD 从 S7150 开始、英伟达从 Turing 架构开始,数据中心 GPU 都支持了 SR-IOV。但是 again,它不是 NIC 那样的 SR-IOV,它需要 Host 上存在一个 vGPU 的 device-model,来模拟从 VM 来的 VF 访问。
所以事实上,到目前为止,GPU 的 SR-IOV 仅仅是封装了 PCIe TLP 层的 VF 路由标识、从而规避了 runtime 时的软件 DMA 翻译,除此之外,和基于 MDEV 的 MPT 方案并无本质的不同。
2.3.7 谱系表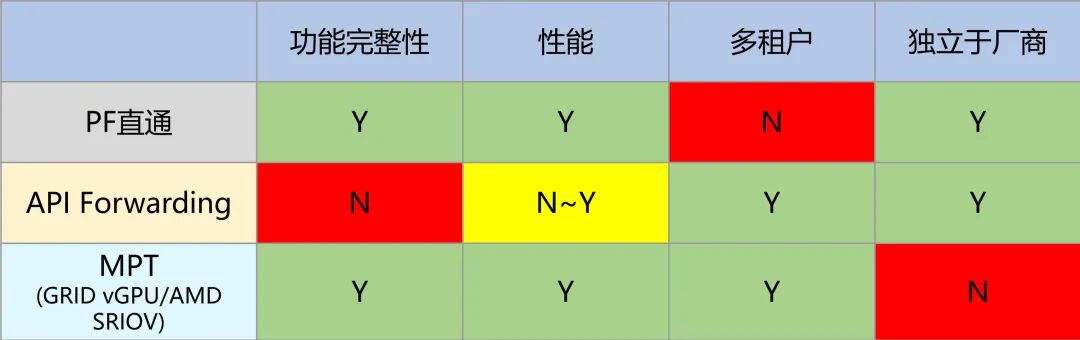
在介绍完了上述的这些方案后,我们重新看下 CUDA 计算、OpenGL 渲染两种场景的软件栈,看看能发现什么:
CUDA 计算 stack:
OpenGL 渲染 Stack:
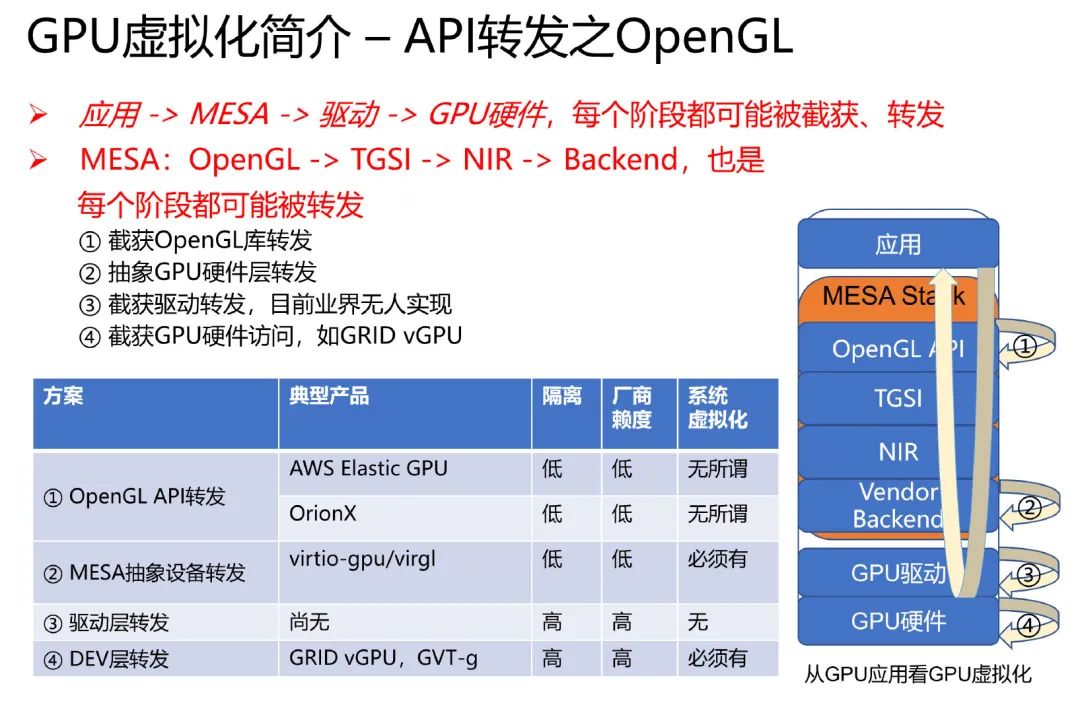
可以看出,从 API 库开始,直到 GPU 硬件,Stack 中的每一个阶段,都有被截获、转发的可能性。甚至,一概称之为「API 转发」是不合适的 —— 以 GRID vGPU、GVT-g 为例的 DEV 转发,事实上就是 MPT,和任何 API 都没有关系。
三、容器 GPU 虚拟化首先,我们这里谈到的,都是 nVidia 生产的 GPU、都只考虑 CUDA 计算场景。其次,这里的虚拟化指的是 OS 虚拟化的容器技术,不适用于 KATA 这样的、基于系统虚拟化的安全容器。
3.1 CUDA 的生态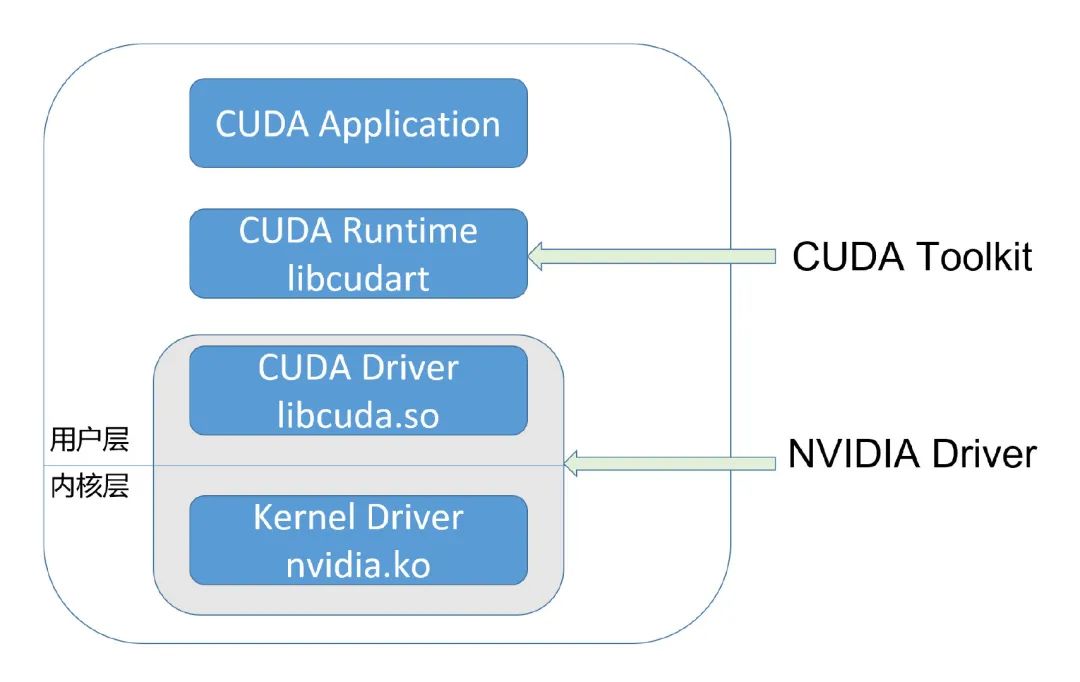
CUDA 开发者使用的,通常是 CUDA Runtime API,它是 high-level 的;而 CUDA Driver API 则是 low-level 的,它对程序和 GPU 硬件有更精细的控制。Runtime API 是对 Driver API 的封装。
CUDA Driver 即是 UMD,它直接和 KMD 打交道。两者都属于 NVIDIA Driver package,它们之间的 ABI,是 NVIDIA Driver package 内部的,不对外公开。
英伟达软件生态封闭:
无论是 nvidia.ko,还是 libcuda.so,还是 libcudart,都是被剥离了符号表的
大多数函数名是加密替换了的
其它的反调试、反逆向手段
以 nvidia.ko 为例,为了兼容不同版本的 Linux 内核 API,它提供了相当丰富的兼容层,于是也就开源了部分代码:
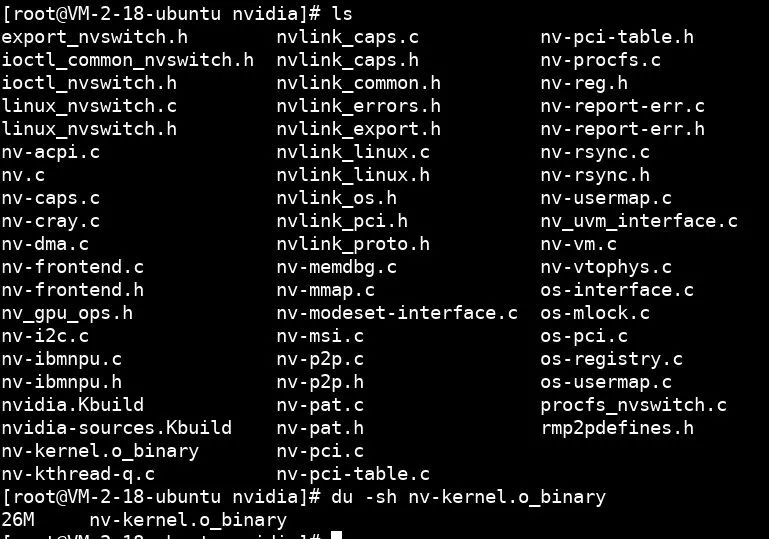
其中这个 26M 大小的、被剥离了符号表的 nv-kernel.o_binary,就是 GPU 驱动的核心代码,所有的 GPU 硬件细节都藏在其中。
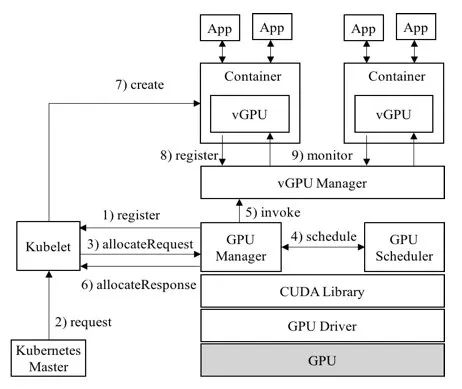
3.2 vCUDA 和友商 cGPU为了让多个容器可以共享同一个 GPU,为了限定每个容器能使用的 GPU 份额,业界出现了不同的方案,典型的如 vCUDA 和 cGPU:
vCUDA 架构:
cGPU 架构:
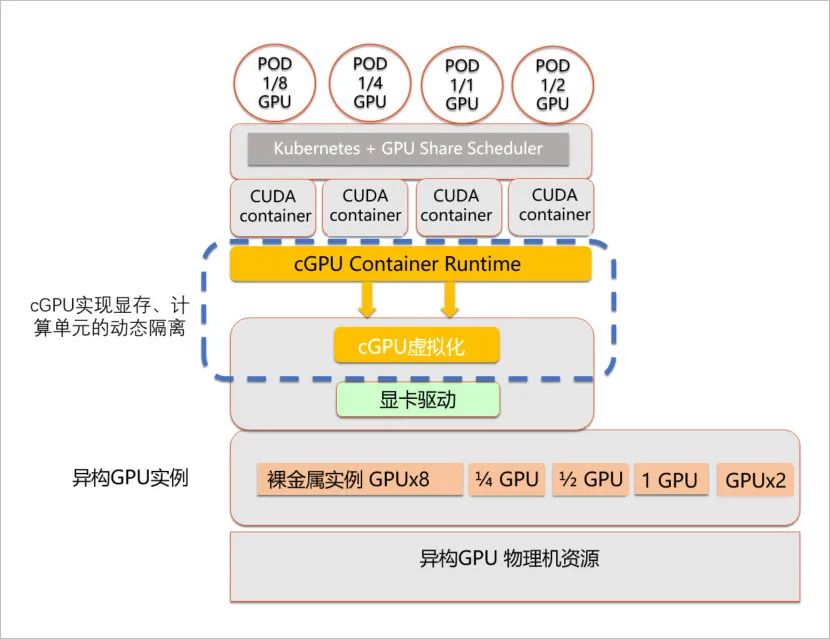
两者的实现策略不同,cGPU 比 vCUDA 更底层,从而实现了不侵入用户环境。
3.3 GPU 池化简介从截获的位置,看 GPU 池化的谱系:
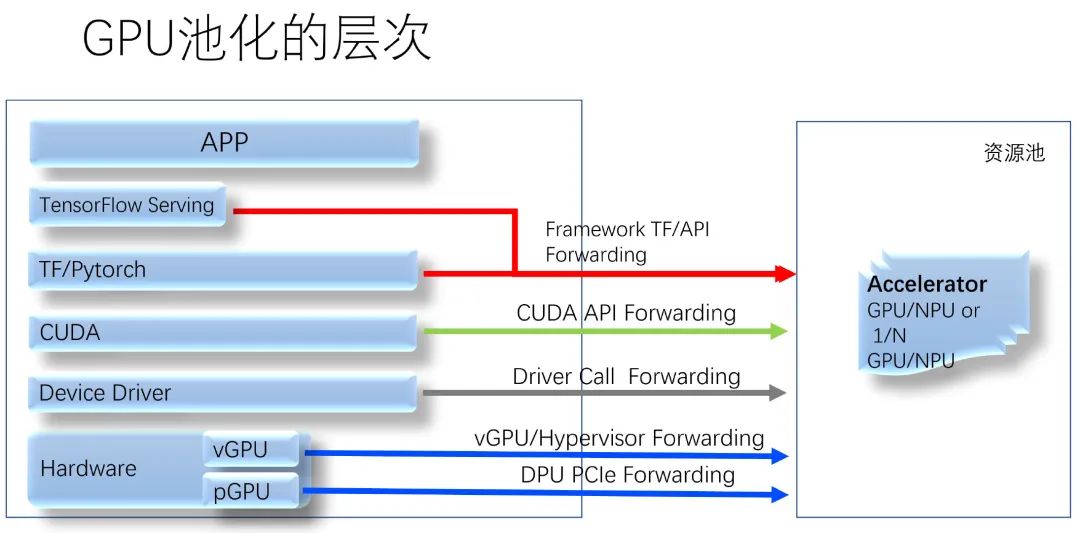
以 CUDA API 转发的池化方案、业界某产品为例,它到了 GPU 所在的后端机器上,由于一个 GPU 卡可能运行多个 GPU 任务,这些任务之间,依然需要有算力隔离。它为了实现这一点,在后端默认启用了 nVidia MPS —— 也就是故障隔离最差的方案。这会导致什么?一个 VM 里的 CUDA 程序越界访问了显存,一堆风马牛不相及的 VM 里的 CUDA 应用就会被杀死。
所以,很显然,GPU 池化也必须以同时满足故障隔离和算力隔离的方案作为基础。
3.4 算力隔离的本质从上述介绍中,我们可以看出:算力隔离、故障隔离都是 GPU 虚拟化、GPU 池化的关键,缺一不可。如果没有算力隔离,不管虚拟化损耗有多低,都会导致其方案价值变低;而如果缺少实例间的故障隔离,则基本无法在生产环境使用了。
事实上,英伟达 GPU 提供了丰富的硬件特性,支持 Hardware Partition,支持 Time Sharing。
1. Hardware Partition,亦即: 空分
Ampere 架构的 A100 GPU 所支持的 MIG,即是一种 Hardware Partition。硬件资源隔离、故障隔离都是硬件实现的 —— 这是无可争议的隔离性最好的方案。它的问题是不灵活: 只有高端 GPU 支持;只支持 CUDA 计算;A100 只支持 7 个 MIG 实例。
2. nVidia MPS
除了 MIG,算力隔离表现最优秀的,是 MPS —— 它通过将多个进程的 CUDA Context,合并到一个 CUDA Context 中,省去了 Context Switch 的开销,也在 Context 内部实现了算力隔离。如前所述,MPS 的致命缺陷,是把许多进程的 CUDA Context 合并成一个,从而导致了额外的故障传播。所以尽管它的算力隔离效果极好,但长期以来工业界使用不多,多租户场景尤其如此。
3. Time Sharing,亦即: 时分
nVidia GPU 支持基于 Engine 的 Context Switch。不管是哪一代的 GPU,其 Engine 都是支持多任务调度的。一个 OS 中同时运行多个 CUDA 任务,这些任务就是在以 Time Sharing 的方式共享 GPU。
鉴于 MIG 的高成本和不灵活、MPS 故障隔离方面的致命缺陷,事实上就只剩下一种可能:Time Sharing。唯一的问题是,如何在原厂不支持的情况下,利用 Time Sharing 支持好算力隔离、以保证 QoS。这也是学术界、工业界面临的最大难题。
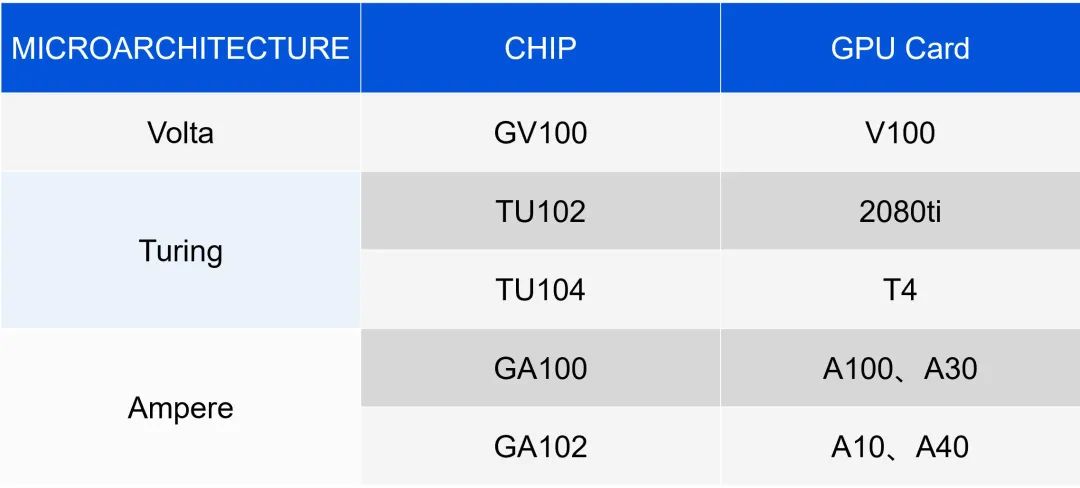
3.4.1 GPU microarchitecture 和 chip真正决定 GPU 硬件以何种方式工作的,是 chip 型号。不管是 GRID Driver 还是 Tesla Driver,要指挥 GPU 硬件工作,就要首先判断 GPU 属于哪种 chip,从而决定用什么样的软硬件接口来驱动它。
PFIFO 架构:
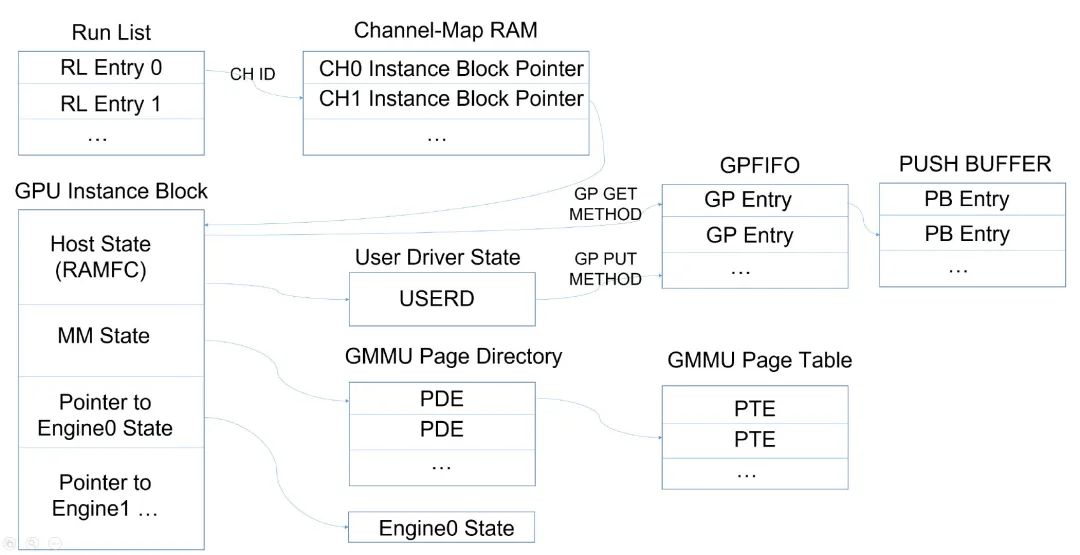
概念解释:
PFIFO
GPU 的调度硬件,整体上叫 PFIFO。
Engine
执行某种类型的 GPU 硬件单元。常见 Engine 有:
PGRAPH —— CUDA/Graphics
PCOPY ——— Copy Engine
PVENC ——— Video Encoding
PVDEC ——— Video Decoding
...
最重要的就是 PGRAPH Engine,它是 CUDA 和渲染的硬件执行单元。
Channel
GPU 暴露给软件的,对 Engine 的抽象。一个 app 可以对应一或多个 channels,执行时由 GPU 硬件把一个一个的 channel,放在一个一个的 engine 上执行。
channel 是软件层的让 GPU 去执行的最小调度单位。
TSG
Timeslice Group。
由一或多个 channel(s)组成。一个 TSG 共享一个 context,且作为一个调度单位被 GPU 执行。
runlist
GPU 调度的最大单位。调度时,GPU 通常是从当前 runlist 的头部摘取 TSG 或 channel 来运行。因此,切换 runlist 也意味着切换 active TSG/channel。
PBDMA
pushbuffer DMA。GPU 上的硬件,用于从 Memory 中获取 pushbuffer。
Host
GPU 上和 SYSMEM 打交道的部分(通过 PCIe 系统)。PBDMA 是 Host 的一部分。注意,Host 是 Engine 和 SYSMEM 之间的唯一桥梁。
Instance Block
每个 Channel 对应一个 Instance Block,它包含各个 Engine 的状态,用于 Context Switch 时的 Save/Restore;包含 GMMU pagetable;包含 RAMFC —— 其中包括 UMD 控制的 USERD。
3.4.3 runlist/TSG/channel 的关系Tesla 驱动为每个 GPU,维护一或多个 runlist,runlist 或位于 GPU 显存,或位于系统内存
runlist 中有很多的 entry,每个 entry 是一个 TSG 或一个 channel
一个 TSG 是 multi-channel 或 single-channel 的
一个 channel 必定隶属于某个 TSG
硬件执行 TSG 或 channel,当遇到以下情景之一时,进行 Context Switch:
执行完毕
timeslice 到了
发生了 preemption
3.4.4 pending channel notificationpending channel notification 是 USERD 提供的机制。UMD 可以利用它通知 GPU:某个 channel 有了新的任务了【1】。这样,GPU 硬件在当前 channel 被切换后(执行完毕、或 timeslice 到了),就会执行相应的 channel。
注释
【1】 不同 chip,实现有所不同。
3.4.5 从硬件调度看 GRID vGPUGRID vGPU 支持 3 种 scheduler:
1. Best Effort: 所有 vGPU 的任务随意提交,GPU 尽力执行。
现象: 如果启动了 N 个 vGPU,它们的负载足够高,那么结果就是均分算力。
原理: 所有的 vGPU 使用同一个 runlist。runlist 内,还是按照 channel 为粒度进行调度。如同在 native 机器上运行多个 CUDA 任务一样。
2. Equal Share: 所有在用的 vGPU 严格拥有同样的 GPU 配额
现象: 如果启动了 N 个 vGPU,它们严格拥有相同的算力,不管是否需要这么多。
原理: 为每个 vGPU 维护一个 runlist。当它的 timeslice 过了,GRID Host Driver 会写 GPU 寄存器,触发当前 runlist 被抢占、下一个 runlist 被调度。
3. Fixed Share: 每个 vGPU 有自己固定的 GPU 配额
现象: 每个 vGPU 严格按照创建时的规格来分配算力。
原理: Ditto.
3.5 腾讯云 qGPU 简介qGPU == QoS GPU。它是目前业界唯一真正实现了故障隔离、显存隔离、算力隔离、且不入侵生态的容器 GPU 共享的技术。
3.5.1 qGPU 基本架构qGPU 基本架构:
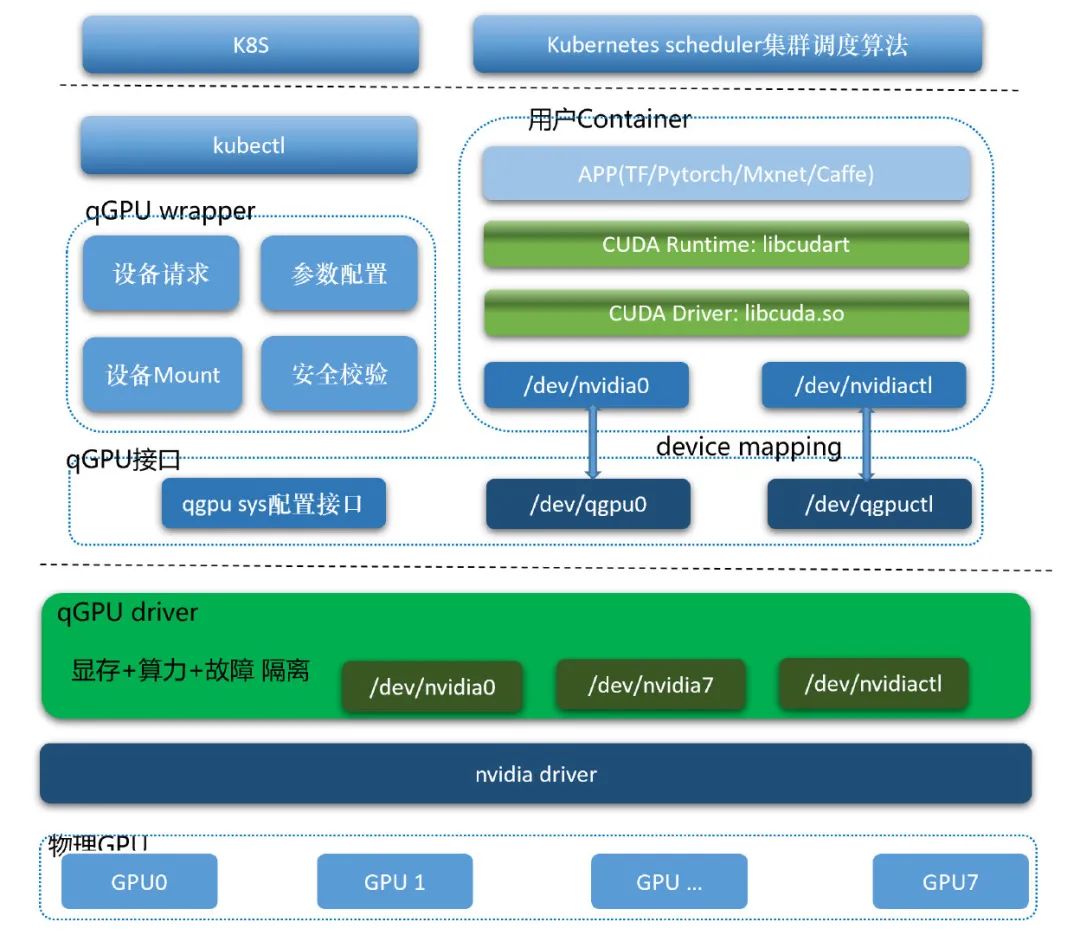
注释
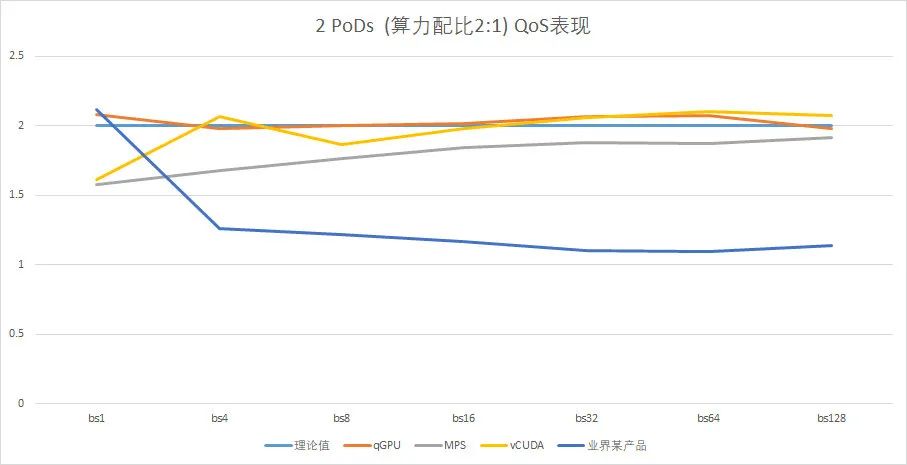
【1】 测试数据来自 T4(chip: TU104)。其它 chip 上,正确性、功能性和性能都待验证,虽然原理上是相通的。
【2】两个 PoD 的算力配比为 2:1。横坐标为 batch 值,纵坐标为运行时两个 PoD 的实际算力比例。可以看到,batch 较小时,负载较小,无法反映算力配比;随着 batch 增大,qGPU 和 MPS 都趋近理论值 2,vCUDA 也偏离不远,但缺乏算力隔离的业界某产品则逐渐趋近 1。
四、GPU 虚拟化: 未来展望2021 以来,GPU 工业界发生了一些变化,e.g.:
1. 英伟达 GPU 的 QoS 突破
英伟达在 CUDA 计算领域占据压倒性的优势,但 QoS 表现不尽如人意。
长期以来,学术界和工业界付出了大量的努力,尝试在英伟达不支持 QoS 的前提下,实现某种程度的算力隔离。遗憾的是,这些努力,要么集中在 CUDA API 层,能够做到一定的算力隔离,但同样会带来副作用;要么尝试在 low-level 层面突破 —— 但不幸全都失败了。
qGPU 是十几年来在英伟达 GPU 上实现 QoS 的最大突破。基于它:
腾讯云 TKE 的多容器共享 GPU,将无悬念地领先整个工业界
在线推理 + 离线训练的混部,成为可能
GPU 池化的后端实现,不管采用哪种方案,都有了坚实的基础
Linux/Android 场景的渲染虚拟化,也有了坚实的基础
2. Vulkan Spec 支持了 video encode/decode
很可能,编解码 API 不统一的乱象即将终结,这对 API 转发方案有很大的意义。不远的将来,或许某种 API 方案的 vGPU 会成为主流。Google 在社区的一些活动标明,很可能它就有这样的计划。
五、参考资料和项目简介1. nVidia MPS
官方。部分文档公开。
2. nouveau driver in Linux Kernel
开源社区版的英伟达 GPU 驱动,基于 DRM,硬件细节基本靠逆向工程。不支持 CUDA、只支持 OpenGL 渲染。代码庞大,包含很多有用信息。
3. envytools 及其 nVidia Hardware Documentation
nouveau 的配套项目。除了提供各种 profiling GPU 硬件细节的工具,还维护了一个文档仓库,记录所有已经被成功逆向了的信息。
4. GDEV project, an opensource implementation of CUDA
基于 nouveau 实现了 CUDA driver 和 CUDA runtime,代码较旧,已不维护。大神级作品。
5. libcudest, a partially RE-ed CUDA driver
英伟达实习生实现的 CUDA Driver 逆向工程。只逆向了一小部分 UMD 和 KMD 之间的接口。已不维护。
6. vCUDA
开源项目。
7. nVidia official: nvidia-uvm driver for Tesla
官方,开源。Telsa Driver 配套的 UVM 驱动,代码开源。和 Tesla Driver 有很多 low-level 交互,可以从中窥见很多 GPU 硬件细节。
8. Tesla Driver
官方。细节全藏在 nv-kernel.o_binary 文件中。
9. GRID vGPU
官方。细节也是全在 nv-kernel.o_binary 文件中。与 Tesla Driver 不同的是,它为 vGPU 的 Fixed Share 和 Equal Share 两种调度策略,实现了 per-vGPU runlist。因此有很高的参考价值。
六、思考 & 致谢"Lasciate ogne speranza, voi ch'intrate." -- Dante Alighieri "Καιρὸν γνῶθι." -- Πιττακός ο Μυτιληναίος
使用 nVidia GPU 进行计算,有两种场景:1) 推理业务,往往是在线业务;2) 训练业务,往往是离线业务。这两种业务之间,很难混部到同一个 GPU 上。甚至两种在线推理业务之间,也很难进行这样的混部。因为没有 QoS 隔离,你不知道哪一个业务会流量突发,影响另一个业务。所以,长期以来,关键的在线业务,GPU 利用率都不高,据我们了解,大多在 50%以下,甚至个别 BG 的推理业务只能到~ 20%。即使 GPU 很昂贵,即使一个业务占不满 GPU,也只能如此。
我们很自然要问:是 nVidia 做不好 QoS 吗?显然不是。MPS 也好,GRID vGPU 也好,其 QoS 表现都很优秀。但是,为什么 MPS 会画蛇添足地引入 CUDA Context Merging 呢?真的是因为这样会带来些许性能上的收益吗?我是持怀疑态度的。在我看来,更可信的解释是,英伟达公司在拥有市场支配地位的情况下,并不希望提升 GPU 利用率。卓越的硬件加上封闭的软件生态,当然能带来丰厚的利润。
学术界、工业界在 CUDA 算力隔离上的努力,这里不再一一列举【1】。这其中既有 GDEV 这样的以一人之力做出的大神级作品,也有毫无营养的灌水式 paper。有意思的是,几乎所有的努力都在上层,很少人有勇气下潜到 GPU 硬件的细节中。我们下潜了,也很幸运地成功了。
感谢腾讯云虚拟化团队的各位同事,一起加班到深夜,分析搜罗到的各种靠谱和不靠谱的项目和 paper,脑补各种可能的软硬件细节,讨论技术上的各种可能性;
感谢腾讯云 TKE 团队的各位同事,协调客户收集需求、协同产品化开发;
感谢 WXG 的同事,和我们一起梳理 GPU 利用率的痛点;
感谢友商的同类产品,它的 idea 无疑是优秀的;
注释
【1】 部分列表可参考阎姝含的文章: 针对深度学习的 GPU 共享:https://zhuanlan.zhihu.com/p/285994980


往期精选推荐


