丰色 发自 凹非寺
量子位 | 公众号 QbitAI
这一夜,AI科技圈热闹非凡:
谷歌搬出“蓄谋已久”的大杀器Gemini,号称直接掀翻GPT-4;
另一边,芯片商AMD也按耐不住,正式发布Instinct MI300X GPU,直接对标英伟达H100。

Instinct MI300X是AMD有史以来最大的芯片——
包含1530亿个晶体管,AI任务推理性能比H100快1.6倍,内存容量足足192GB,是H100的两倍以上(2.4x)。

它的出现,无疑为业界提供了颇有竞争力的第二种选择。
消息称,微软、Meta、OpenAI和Oracle等一众公司已率先承诺将购买AMD的这款GPU来替代H100。
AI加速芯片的市场,是否就此开始改变?
推理性能比H100 HGX快1.6倍,最高支持2900亿参数
AMD在6月就预告了这款芯片,今天是正式发布,公布参数等细节。
据介绍,Instinct MI300X是AMD使用有史以来最先进的生产技术打造,是Chiplet设计方法的“代表之作”。
它的底层是4个6nm I/O芯片,上面融合了8个HBM3内存(12Hi堆栈)和8个5nm CDNA 3 GPU小芯片(3D堆栈)。
其中3D堆叠GPU和I/O芯片通过“3.5D”封装技术进行连接。
最终成品功耗750W,包含304个计算单元、5.3TB/s带宽,以及高达192GB的HBM3内存(相比之下,H100仅80GB)。

在实际的生成式AI平台应用中,MI300X被设计为8个一组 ,通过Infinity Fabri进行互联,各GPU之间的吞吐量为896 GB/s。

同时,这一组合的内存总量达到1.5TB HBM3(H100为640GB),可提供高达10.4 Petaflops的计算性能 (BF16/FP16)。
与英伟达的H100 HGX平台 (BF16/FP16) 相比,内存总量增加2.4倍,计算能力提高1.3倍。
与此同时,AMD还为MI300X配备了400GbE网络并支持多种网卡,比英伟达的选择更多。
下面是AMD分享的官方性能测试结果(理性参考)。
首先,对于HPC工作负载,MI300X的FP64和FP32向量矩阵理论峰值吞吐量是H100的2.4倍;对于AI工作负载,其TF32、FP16、BF16、FP8和INT8理论峰值吞吐量是H100的1.3倍。
注意,这些预测都不包含稀疏性(尽管MI300X确实支持)。
其次,AI推理任务中,AMD以1760亿参数的Flash Attention 2为例,声称MI300X在吞吐量(tokens/s)方面比H100高出1.6倍,同时,在700亿参数的Llama 2上,聊天延迟更慢,比H100快1.4倍(基于2k序列长度/128token workload)。
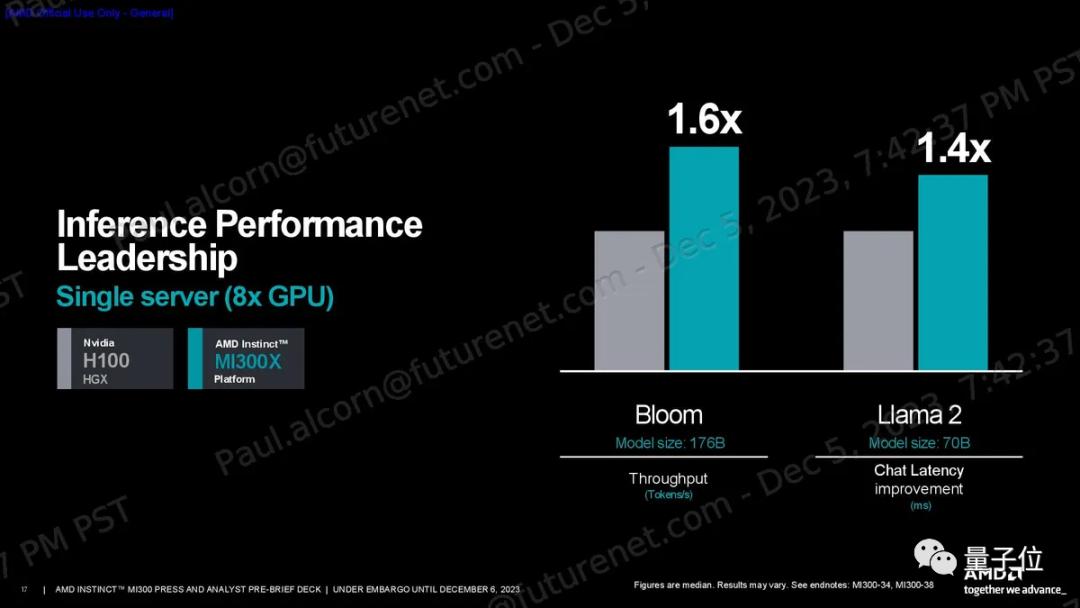
不得不说,MI300X的大内存容量和带宽确给它带来了这一不小的优势。
相比之下,在训练任务上,MI300X在300亿参数的MPT上的性能倒是与H100 HGX大致相同。

所以总的来看,MI300X的优势更在于推理。
此外,还需要强调的是,MI300X由于内存容量实在更大,因此可以容纳比H100多两倍的300亿参数训练模型、700亿参数的推理模型。
以及MI300X最多可支持700亿训练和2900亿参数的推理模型,这都比H100 HGX多一倍。
最后,大伙最关心的价格——苏妈没说,但表示“肯定、必须低于英伟达”。
目前,AMD已经向HPE、戴尔、联想、SuperMicro等原始设备制造商发货,正式发售时间定于下季度,也就是明年。
说到2024年,AI加速芯片市场将无比热闹:
除了AMD的MI300X,英特尔也将升级其Gaudi架构GPU,以及英伟达H200也要在2024年Q2问世。
Tomshardware表示,H200在内存容量和带宽方面大概率会更上一层楼,计算性能则预计将和MI300X差不多。
最后,在发布会上,苏妈也预测,2027年AI芯片总市场将达到4000亿美元。而她认为,AMD有信心从中分走一块还不错的蛋糕(get a nice piece of that)。

全球首款数据中心APU也来了
本场发布会上,和Instinct MI300X一共亮相的还有Instinct MI300A。
前者专供生成式AI领域,后者则主要用于HPC计算。
据悉,MI300A是全球首个数据中心APU,CPU和GPU结合在同一个封装之中,对标的是英伟达Grace Hopper Superchips ,后者CPU和GPU位于独立的封装中,再串联到一起。
具体而言,MI300A采用和MI300X相同的基本设计和方法,但包含3个5nm核心计算芯片(CCD),每个配备8个Zen 4 CPU,所以一共24线程CPU核心,外加228个CDNA 3计算单元。
内存容量上,相比MI300X中的8个12Hi堆栈,它改为8个8Hi堆栈,从而将容量从192GB缩减至128G,内存带宽仍为5.3TB/s。
这样的结果仍然是英伟达Nvidia H100 SXM GPU提供的1.6倍。

据悉,MI300A已开始用于美国劳伦斯利弗莫尔实验室,基于该芯片,该实验室的El Capitan有望成为世界首台2 Exaflop级别的超级计算机。
One More Thing
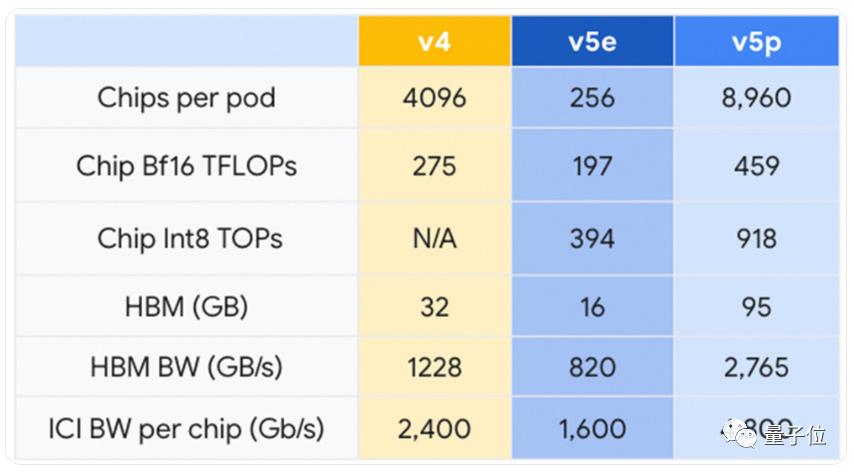
就在同一天,谷歌也发布了最新AI芯片:TPU v5p。
它主要和前代相比:
bfloat16性能提升至1.67倍,内存容量增至95GB,新增int8运算,速度为918 TOPs等等。
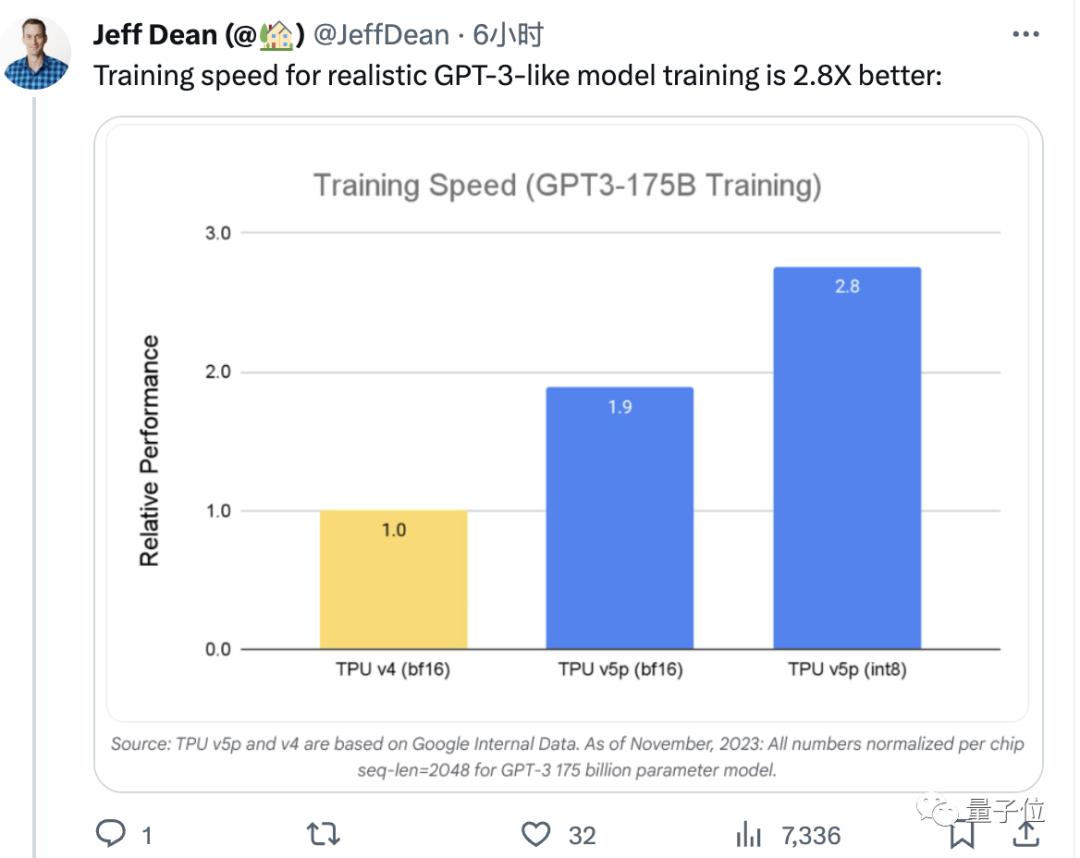
具体到模型上,用它训练一个类似GPT-3的1750亿参数模型的性能将提高2.8倍。
参考链接:
[1]https://www.tomshardware.com/pc-components/cpus/amd-unveils-instinct-mi300x-gpu-and-mi300a-apu-claims-up-to-16x-lead-over-nvidias-competing-gpus
[2]https://www.cnbc.com/2023/12/06/meta-and-microsoft-to-buy-amds-new-ai-chip-as-alternative-to-nvidia.html
[3]https://cloud.google.com/blog/products/ai-machine-learning/introducing-cloud-tpu-v5p-and-ai-hypercomputer
— 完 —
科技前沿进展日日相见 ~
原标题:《H100最强竞品正式发布!推理快1.6倍,内存高达192GB,来自AMD》
