
谈及“数据新闻”,我们通常有两种操作思路:一是通过「数据挖掘」(data mining),找到新闻点;二是在已有的新闻中,添加呈现数据的元素。
其中,“数据挖掘”指从数据库中寻找到有价值新闻点。这些从数据库中爬取的信息可能会给新闻调查带来新的调查思路。最终呈现出来的作品也许根本就没有完全反映数据的使用,好像还是传统新闻那样,主要还是内容仍旧是采访与照片。但其实这整个的新闻热点,都是科学地由数据挖掘而来。
另外一种方式,便是用数据来呈现、解释新闻点。其中会涉及多种图表和一些交互性功能的使用,在科学领域我们通常称之“数据可视化”。
本篇文章侧重讲解“数据挖掘”(data mining),也就是探讨如何从数据中挖掘新闻,或者说,找到新闻线索。

从新闻线索发展为一个完整的新闻故事,则需要结合传统的和新兴的新闻操作手法。
本篇文章中,为了方便讨论,我们使用“新闻”广义的定义——公众获得了他之前所不了解的信息,也可以理解为“新的信息”。所以“新闻”有可能是当前事件的最新状态,或是对读者来说的“新知识”。
(某些知识可能对于一些领域的专业人士是常识,但对于普通受众而言,那就是全新的知识了。)
正如中文常说的“大道至简”:最复杂的理论往往是用最简单的语言构建 。
所以我们其实不用难懂的编程技巧,抛开复杂的电子表格工具(spreadsheet),只用一些最最基础的计算机常识(computer literacy),再加上我们敏锐的新闻嗅觉,就已经可以从数据中找到很多有意思的“新闻点”了。
接下来,我们会通具体的例子来进一步解释如何在数据中寻找新闻。
这些例子都来源于新闻系的本科生。
这些数据表,是这些本科生们,在数据新闻的第二堂课上,用仅仅二十分钟时间,从香港政府网站上爬取下来的。
我们从网站的公共数据集开始,仔细审视这些数据表,来寻找有趣的新闻点。
这个过程十分快速,以至于我们给它取了一个猴塞雷的名字:「闪电新闻」(Lightning News)。
那么,应该如何提高自己“Lightning News”的能力呢?
大量的日常训练!
大量的日常训练!
大量的日常训练!
大量的日常训练后,新闻敏感性和数据敏感性都会有很大提升。
让我们从这篇文章开始日常训练的第一步吧!


【分析】
1. 最后一排展现的是香港过去几十年的年龄变化情况。
2. 比较男性和女性的年龄中位数,重点关注红色圆圈圈起来的数字,我们发现:不包含外籍家庭佣工的情况下,女性普遍比男性年长。
3. 单看男性的数据,我们可以发现,包含和不包含外籍家庭佣工的两组数据并没有显著的差异。
问题就来了:是因为没有男性的外籍家庭佣工吗?还是有数据背后隐藏着细小的区别呢?事实是,还真有男性的外籍佣工存在。
所以接下来,你就可以进一步去挖掘他们的故事了。
02 数据库:政府在教育方面的开支

【分析】
很容易发现,政府在教育上花费的开支绝对数字是在增长的(绿色方框标注),但是教育开支占所有开支的比例却是在减少的(红色方框标注)。
那么,新闻线索便呼之欲出:政府在教育上的投入到底是增加了?还是减少了?
03 数据库:按种类划分的平均固体废物数量

【分析】
1.相比之前的例子,这张图表上有更多有价值的数据点。
通常情况下,为了便于更清楚地发现最重要的信息,我们会使用“低亮”(与“高亮”相反的操作)的方法,即通过灰白色来隐藏一些繁琐的细节。
在序列数据中,它的起点/终点/中间点这三部分是我们最关注的。
当拿到一张图表示,你只需要快速扫视图表中的的这三个关键数据,便能很快判断出整体的变化情况。
变化情况一般分为四种:上升,下降,先下降后上升或者先上升后下降(符号表示:/, , V, ^)。

举例如下:
这场图表总体来看,【城市固体废物】排放量不断增加,其中【生活垃圾】略有减少,【商业垃圾】几乎翻了一番,而【工业垃圾】则增加了一半。
通过以上信息分析,【商业类】和【工业类】固体废物的迅速增长,是否表明城市经济正在进行结构上的转变?
注意,这些数据还很适合通过折线图的方式进行展示。
详细可参考HOWTO 这篇文章(点击阅读原文观看)和下面的例子:

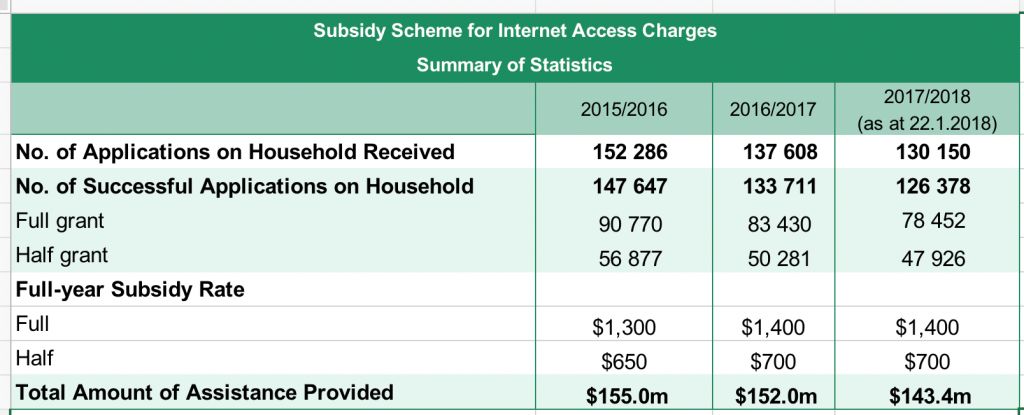
分析
1. 从图表中我们发现,无论是申请补助计划的人数,以及申请成功的案例,其数量都在减少。
2. 那么,是什么原因导致没有那么多成功的申请者的呢?
这种趋势是否表明整体经济形势在变好,所符合补助资格的人数在变少?
或者仅仅是因为申请成功的标准在变严格?
05 15岁及以上人口的教育程度分布
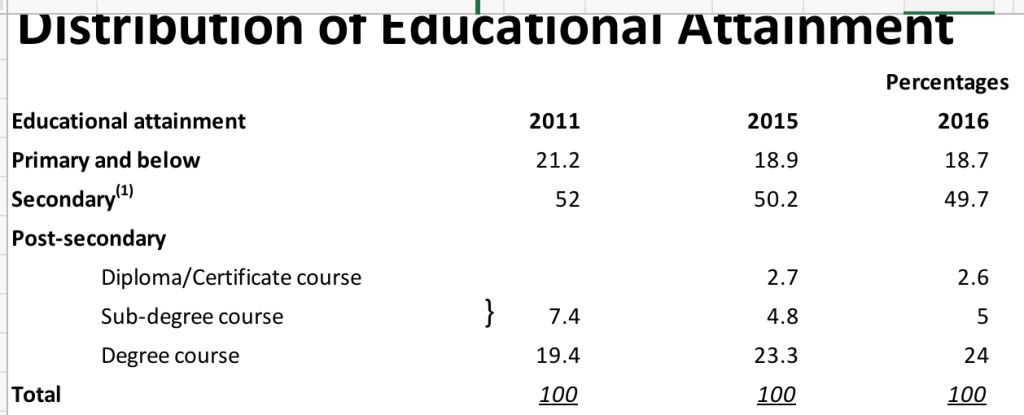
分析
1.从上表中我们发现,教育程度在「小学及以下」和「中学」的人数在减少。这是否表明全民教育成功普及?
或只是因为年轻人教育程度普遍较高,同时低学历的老年人去世,导致教育程度较低的人数整体减少?
2.学位课程有哪些潜在途径?更普遍的问题是,小学毕业后,学生的教育路径/职业晋升路径是什么?
互联网的发展让很多非本地读者也能浏览到当地的新闻。
只经历过数十年标准化/统一教育体系的内地读者很快就会发现,在香港,中学教育通常跨越5-7年,大学教育跨越2-5年。这和内地的教育体系有很大的不同。
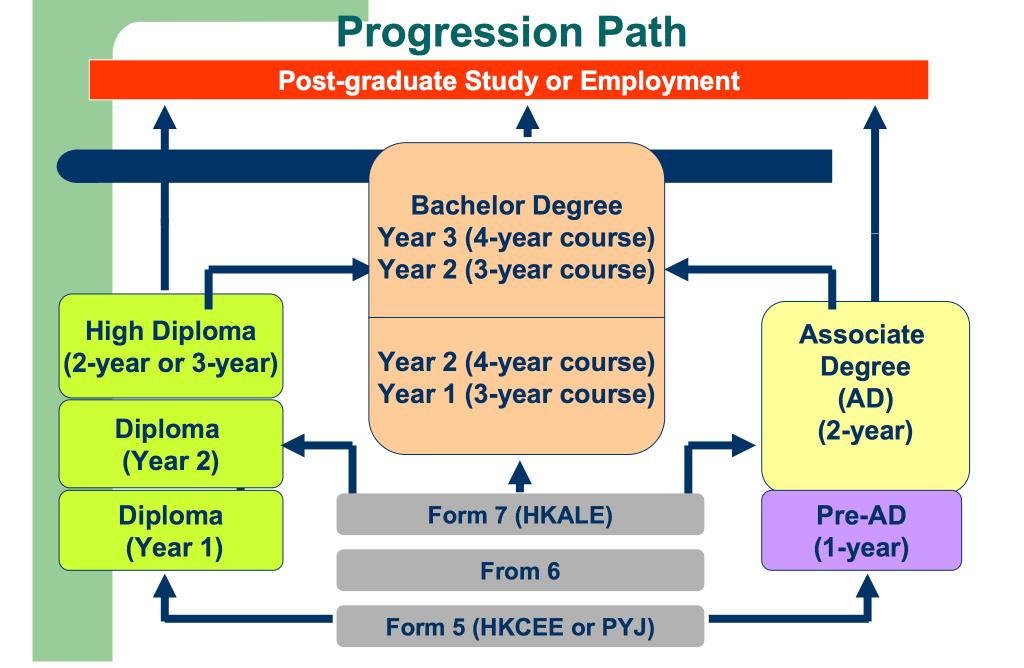
?download=80:jul29-post-secondary-education-in-hong-kong-profkwan
06 跨境(内地和香港)车流量
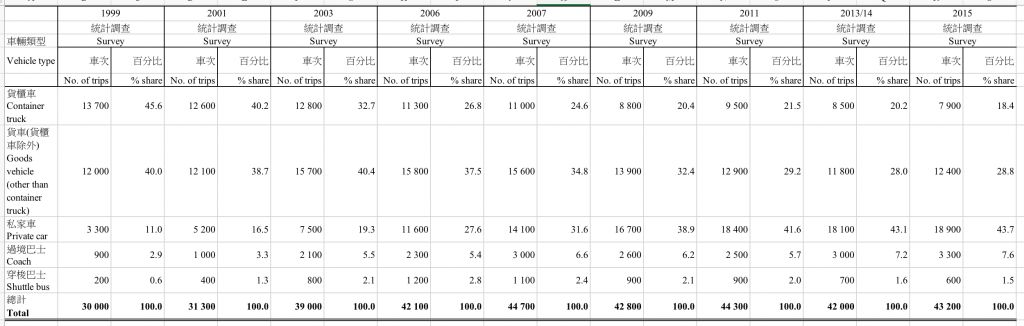
分析
1.上图是按类型和年份统计的过境巴士数量表格。可以看到,过去16年间,跨境车辆的数量有了很大的变化。最明显的一点:过境的人变多了,过境的货变少了。
2.这种趋势是否意味着两边的交流变多?抑或这种现象是由于边境政策放松所导致?
3.进一步挖掘表内信息,比如,工作日流量,边境管制点流量,香港境内/目的地流量,香港境外/目的地流量,乘客人数百分比,以旅行为目的,在香港/大陆逗留的时间等等,恰好可以回答了我们在新闻生产中常常会问到的六个问题:who, what, when, where, how and why。
单一的数据往往不能回答我们以上的所有问题。当我们发现有价值的新闻点时,我们需要做更全面的调查进一步的挖掘背后的故事,以6个W的问题为线索深入。
PS:拿到数据后,我们首先要注意清晰主要的故事点,而用波形图(Sparkline)来展示数据的变化是一个很不错的方式。
但在绘制折线图之前,我们首先要对原始数据进行整理。
另外需要注意的是,Excel2010及之前的版本或者是在兼容模式之下,是不能用折线图的,所以我们可以在处理数据之前,另存为新的格式,或者重新打开Excel。


分析
纵观香港三个主要地区近年的人口变化(绿色框),香港岛的人口在减少,而九龙和新界的人数有了很大程度的增加。
根据所发现趋势,我们可以进一步思考:这种趋势的发生是自然出生/死亡率下的正常波动导致的呢?还是因为新界和九龙地区更适宜居住,导致了人口的大量迁移?
由红色框数据可知,整体来看,香港岛的人数在下降,但香港岛南部的人数却没有下降,反而有细微的增加。是否是因为此地区近年交通运输方式的改善(比如南港岛线)?还是因为近年此地区提供了更多的工作机会(比如说,香港岛南部的数码港)?
08 二零零七年食物中毒病原体统计数字
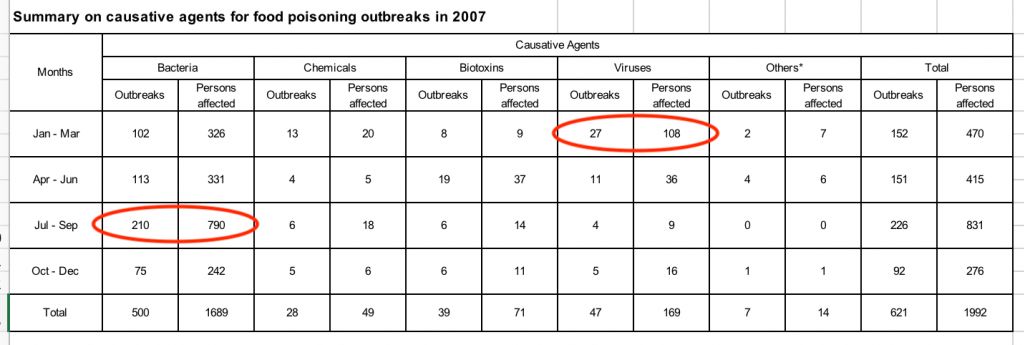
分析
1.二零零七年的食品中毒案例中,细菌和病毒是两个主要病原体。
2.细菌病原体导致中毒的事件主要发生在夏季,而病毒病原体导致的中毒事件主要发生在冬季。
不同病原体导致的中毒事件的发生根据季节变化有明显不同,季节是否为其中重要的影响因素?还是2007年有特殊的事件发生?
产生这样的疑问后,一方面,为进一步验证我们的猜测,我们需要查找更多年份的相关数据。
另一方面,我们也得到了一个重要的信息:季节是食物中毒的重要影响因素。
可见,数据库中的异常值是应该重点关注的,它们很有可能给我们带来一些新的思考。
09 工资指数

分析
1.最后,上图是一个已经进行过可视化的图表,从中我们依旧可以关注到一些有意思的信息,譬如,金融保险行业在近几十年中平均工资始终遥遥领先,另外,除了制造业以及能源产业,其余行业与金融行业间的工资差距在慢慢减小。
2.但,仅凭这样一张图表就开始撰写新闻显然是不严谨的,我们需要始终葆有怀疑的态度,进一步检查所用数据是否有一定的局限性。
图表的左上角的标示显示,这些数据展示的“中层经理与专业人才”的薪金变化。
表中数据是在这样有职位限制的情况下收集的,这就能很好地解释为什么各行业之间的平均工资差距比我们印象中的要小很多,这是因为所收集的数据都来自各行业内的管理层人员。
方法总结
通过以上的案例分析,我们总结出两种从数据中挖掘新闻的方法。
一种是纵观所有数据后,寻找趋势,模式,共同规律,普遍现象。
另一种是寻找数据中的异常,由此探讨异常背后的原因。
那么,如何寻找趋势呢?
一个比较快速便捷的方式是,我们可以通过抓取起点值/中点值/终点值迅速分析数据的大致变化趋势(是上升?还是下降?是先降后升?还是先升后降?)
不过,尽管数据可视化图表可以让我们清晰观察到整体趋势,我们依然需要根据实际情况进行进一步的分析和判断。
那么又如何寻找异常呢?
最有效的方法是关注最大值和最小值。
相比寻找到数据的平均值/中位数,最大值和最小值更易被发现。
对于复合结构或者多维结构的数据表格来说,向下钻取数据(drill-down)非常有用,常常被应用地理纬度表格,以及日期时间纬度表格。
当发现一个新闻/新闻点时,我们需要通过询问6个W的问题进一步推进。
在数据领域,这时,我们就需要查找其他相关的数据,找到更有力的证据。
最后需要注意的是, 数据常常可以直接回答我们Who/What/When/Where这几个问题,
很少回答我们关于How的问题,
而几乎不会回答我们关于why的问题。
此时,就要靠高素质的新闻记者去查证,挖掘出新闻点背后的真相,回答how and why了。
原文首刊登于The Data & Society News
